反爬盒子Traffic Purifier

什么是爬虫?
当我们想在互联网上查找信息时,通常的操作是打开百度,通过关键字搜索到高质量的匹配结果。
• 那么百度里的数据又是哪里来的呢?
• 可以简单理解为:
百度用计算机程序编写了一个极高性能的网络机器人
代替访问者持续访问(爬)到互联网上的全部资源并收录,并反链出处。
这个网络机器人,就是我们常说的网络爬虫,英文名:web crawler。
• 伴随信息技术的高速发展,现在的爬虫,其爬取策略不断提升
因此搜索引擎的返回结果质量也越来越高,为广大互联网用户提供了很多便利
• 厂商之间也积极构建“礼貌”的爬取协议,尊重版权与信息出处的意愿,这本是一项造福人类的技术成果。
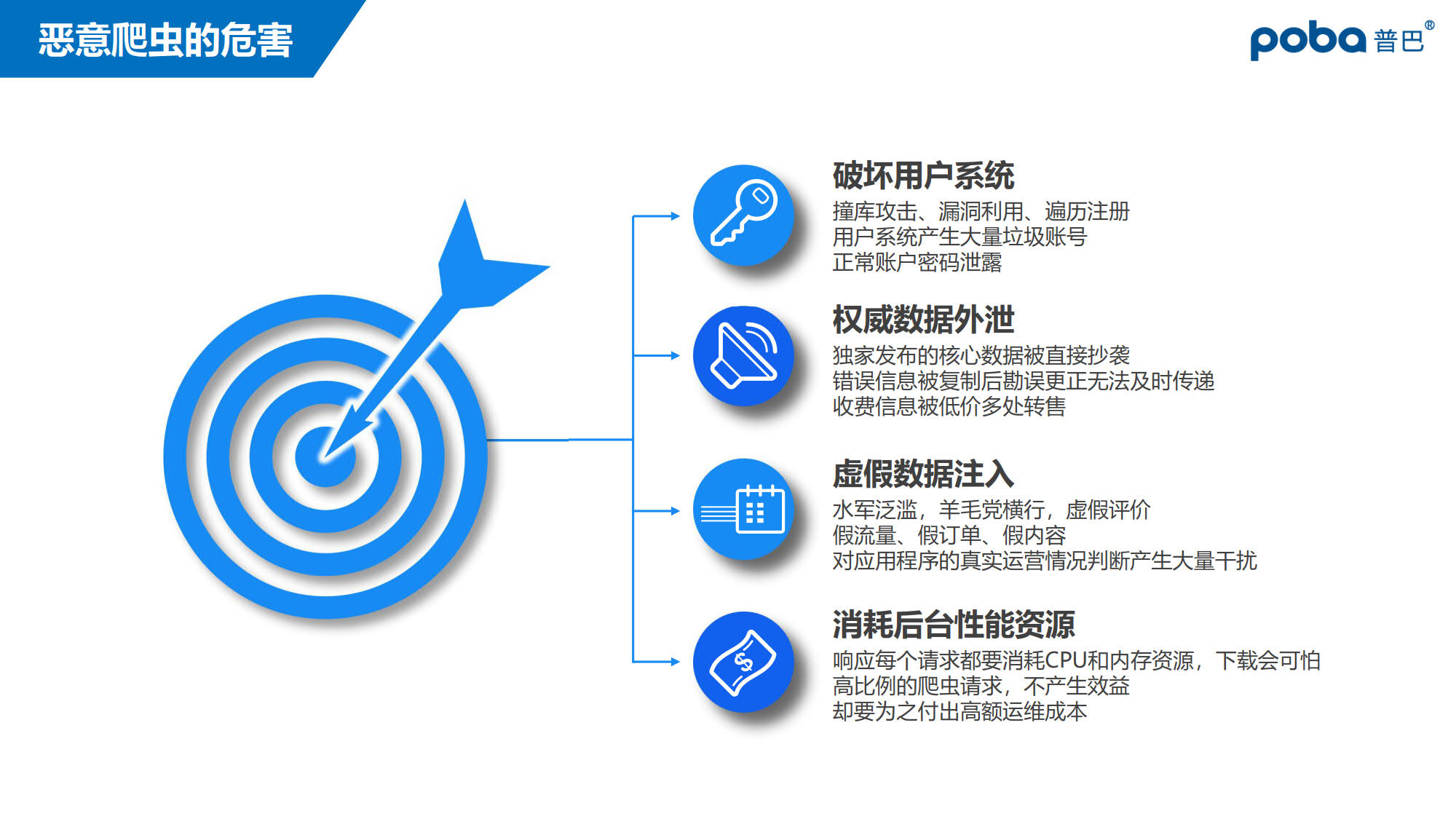
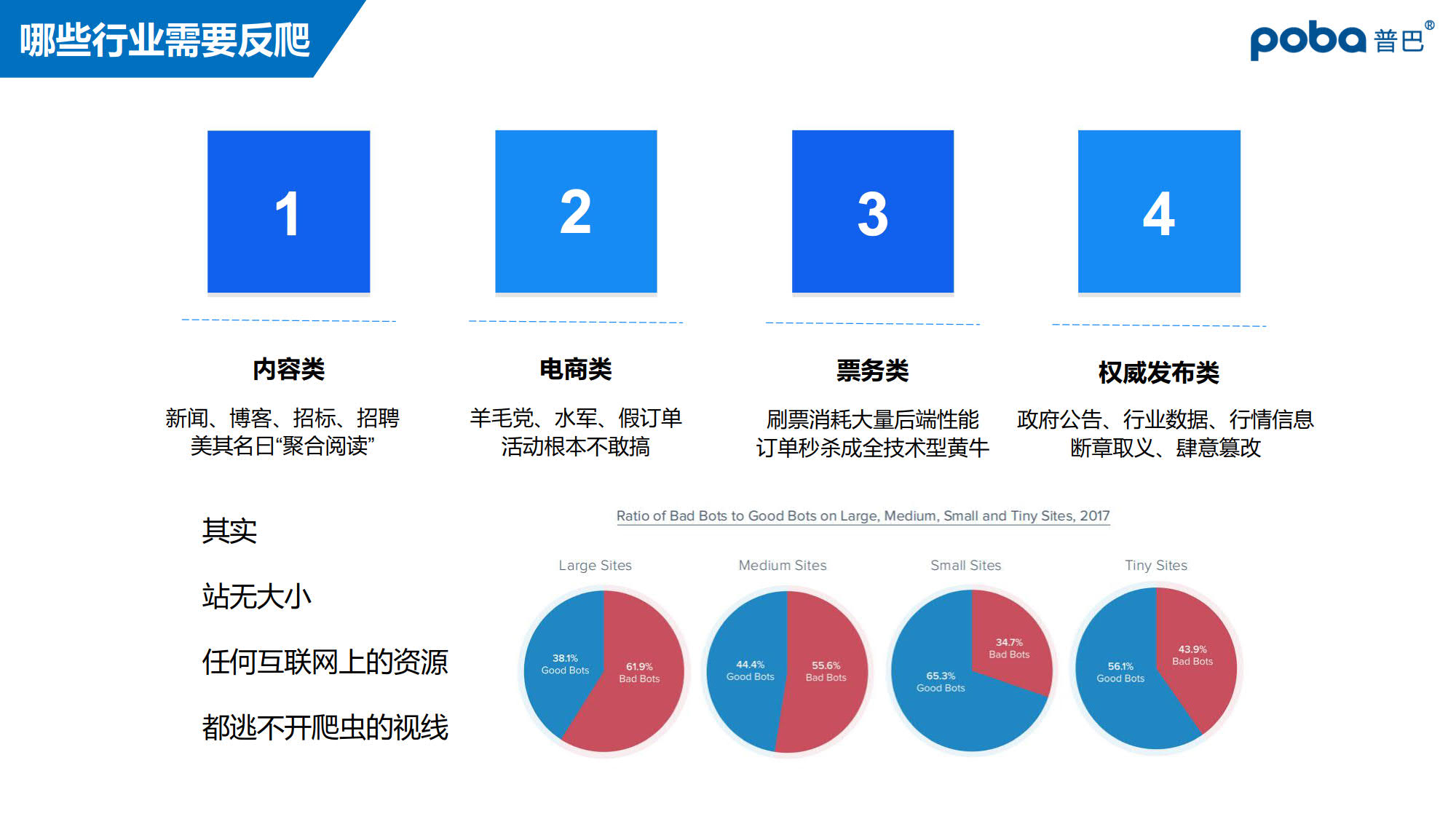
然而,您是否有想过,这项技术,一旦被恶意使用,会是怎样的一个画面?